Is This Book Worth My Time? An Optimal Rating Threshold Approach
05/2026
This week at the CETC, I attended M. Murphy’s talk on optimal review design. This post leans on his paper, “Clicks or Comments? The quality-quantity trade-off of review systems”, to solve a very pedantic problem. It was written across conference sessions, so errors are both highly likely and entirely my own.
The Book-Selection Problem
I have a decent number of friends who read a lot, and also happen to be tapped into the social-media-literary-scene. For someone who gets most of their books from the seconds store down on Main Street, my exposure to literature that is new and hot is also largely secondhand. I don’t watch short (or long) form content about books, and the only person whose reviews I bother reading are mine (for spelling errors). I do no research before I buy the book, and have developed my current taste in the most informationally inefficient way possible, through haphazard trial-and-error.
This lends itself to ~10% of books I read each year being bad. I read ~50 books a year at the rate of one book per week, which means I have 5 whole weeks where I’m reading something that (a) doesn’t conform to my tastes, or (b) is objectively bad writing, or (c) both. This is an incredibly irrational way to consume written media.
To fix ideas, consider a simple utility function for reading a book:
Let your idiosyncratic taste be a fixed set of attributes $\mathcal{K}$. Assume that the utility ($U_b$) from reading a given book $b$ is increasing in both $\lvert\mathcal{K’}\rvert$ and objective literary merit ($m_b$). Here, we let $\mathcal{K’} \subseteq \mathcal{K}$ be the attributes contained in $b$ that satisfy your idiosyncratic tastes. To maximise $\mathbf{E}[U_b]$, you should determine $m_b$, and maximise $\lvert\mathcal{K}’\rvert$ through research, prior to purchase. For this exercise, I’m assuming that you have perfect knowledge of your tastes, and $m_b$ is a constant.
My method of book choice makes crude approximations of $m_b$ and $\lvert\mathcal{K’}\rvert$, as determined by the book cover. To add some more information to my decision, I have recently begun to peruse Goodreads for their average rating. The average rating on a large enough sample marginally improves my estimate of $m_b$, but does nothing for my tastes (this is fine by me, because I like to be surprised). Unfortunately, this is what the Goodreads rating distribution looks like:
Now it’s entirely possible that the modal rating is a good decision rule — if the book scores $\geq 4$ stars, I should just buy it, but I’m a little skeptical about the modal rating being so high. This post will primarily focus on determining $m_b$ using Goodreads ratings. For a minute though, let’s consider the taste parameter, which I could solve for by reading users’ text reviews. This is still pretty noisy, because (a) the likelihood that I stumble across a user with my $\mathcal{K}$ (or a large subset of it) is pretty low, (b) I simply do not have the time to comb through people’s reviews, and (c) spoilers.
A good alternative to reading text reviews is social media, which is a relatively low-cognitive-effort tool for optimising taste-based consumption. BookTok (the literary corner of TikTok) emerged in 2019, and it doesn’t take a genius to know that popular content is taste-making. BookTok features creators who review books, providing detailed information on the content, theme, and genre (topped off with their personal experience). Popular videos have likes, reposts, and shares, which is a form of reviewing the review itself. If we assume that knowledge of the book’s true quality is increasing in the number of reviews ($n$) (and reviews of reviews), then TikTok is an excellent resource to maximise $\mathbf{E}[U_b]$.
Aside: It also leads to taste convergence. Creators review more of the same books, creating a commercial feedback loop of epic proportions. Everyone is reading and talking about the same books, their adaptations, and their not-so-creative boilerplate bubble-font cartoon covers.
The advantage of consuming books that are “reviewed” $n$ times is massive — content has tags that let you filter for themes you enjoy, likes and comments provide enough information to predict with near certainty your utility from consuming the book. The rational agent always consumes the product with the highest expected utility.
Aside: If you heavily use and rely on BookTok (or any content-creator based book-review system), then you can achieve $\mathbf{E}[U_b] = U_b$ by searching for a creator that has the same $\mathcal{K}$ as you. The original utility maximisation problem requires you to re-compute expected utility for each book you pick up. Choosing a creator with the same set of preferences as you eliminates this cognitive effort (assuming both your and the creator’s set of preferences stay fixed).
This is bad news for me. I don’t consume the content about books, and have already ironed my priors into a Hemingway-circlejerk shape, so the only review I do occasionally lean on is an average Goodreads rating. Why? If it’s above $20 (thank you, Canadian Publishing), and I have never read anything by the author, I appreciate some wisdom from the crowd. I suspect that at this point, the cost of curating a literary algorithm on any social media will require considerable interaction that I don’t want to partake in. Which leaves me archaically stranded on the now Amazon-owned-and-unchanged-since-2012 website.
This is incredibly unhelpful, because 5-star rating systems are right-skewed. Curating an algorithm that gives me detailed reviews imposes a higher cost than reading the raw rating averages on Goodreads and making a buy-or-not decision. It’s similar to the tradeoff problem that platforms face while designing a review system — they can elicit many coarse responses, or fewer detailed responses. Reducing the number or complexity of questions that a reviewer must answer increases the likelihood that she will complete the review (Bean and Roszkowski 1995) at the cost of the information contained in each review. For me, this means that I could either get the average of a large number of coarse reviews instantly, or spend more time listening to one long and detailed review.
So I want to continue to use my Goodreads “look at the average” system, but with some confidence. To do this, I’ll take Murphy’s paper to Goodreads data and compute the optimal rating threshold that determines which books are worth my time.
The Model
Assume that the optimal review system is binary, and I want to determine some threshold value $k$ such that all books rated $k’$, for $k \leq k’$, are good, and I should buy them. For simplicity, I’ll stick to the paper’s language and motivate the review threshold decision for the platform, but it doesn’t change the spirit of this exercise.
Goodreads wants to design a review system that allows it to determine the unknown quality of a book. The platform chooses a review system (1–5 stars), and reviewers use their private signals and benefits to submit a review (private benefit from submitting a review, net of cost). The platform observes the set of submitted reviews, and then chooses to update its belief on the quality of the book.
A key assumption of this model is that the probability a reviewer submits a review is independent of a reviewer’s signal realisation. This is unrealistic: in practice reviewers with more extreme signals are more likely to submit reviews (Lafky 2014; Hu, Pavlou, and Zhang 2017). Common review systems, like 5-star reviews, are difficult to fine-tune because of reviewers’ extensive experience with similar systems: reviewers are likely to default to their own, private, thresholds (Botelho et al. 2025). Which is precisely why we’ll try to motivate a binary system, by solving for a threshold.
Note: We’ll hand wave over quite a bit of theory, but the key insight here is that the symmetric binary review system is the optimal binary review system if and only if reviewers are sufficiently heterogeneous.
Data and Heterogeneity
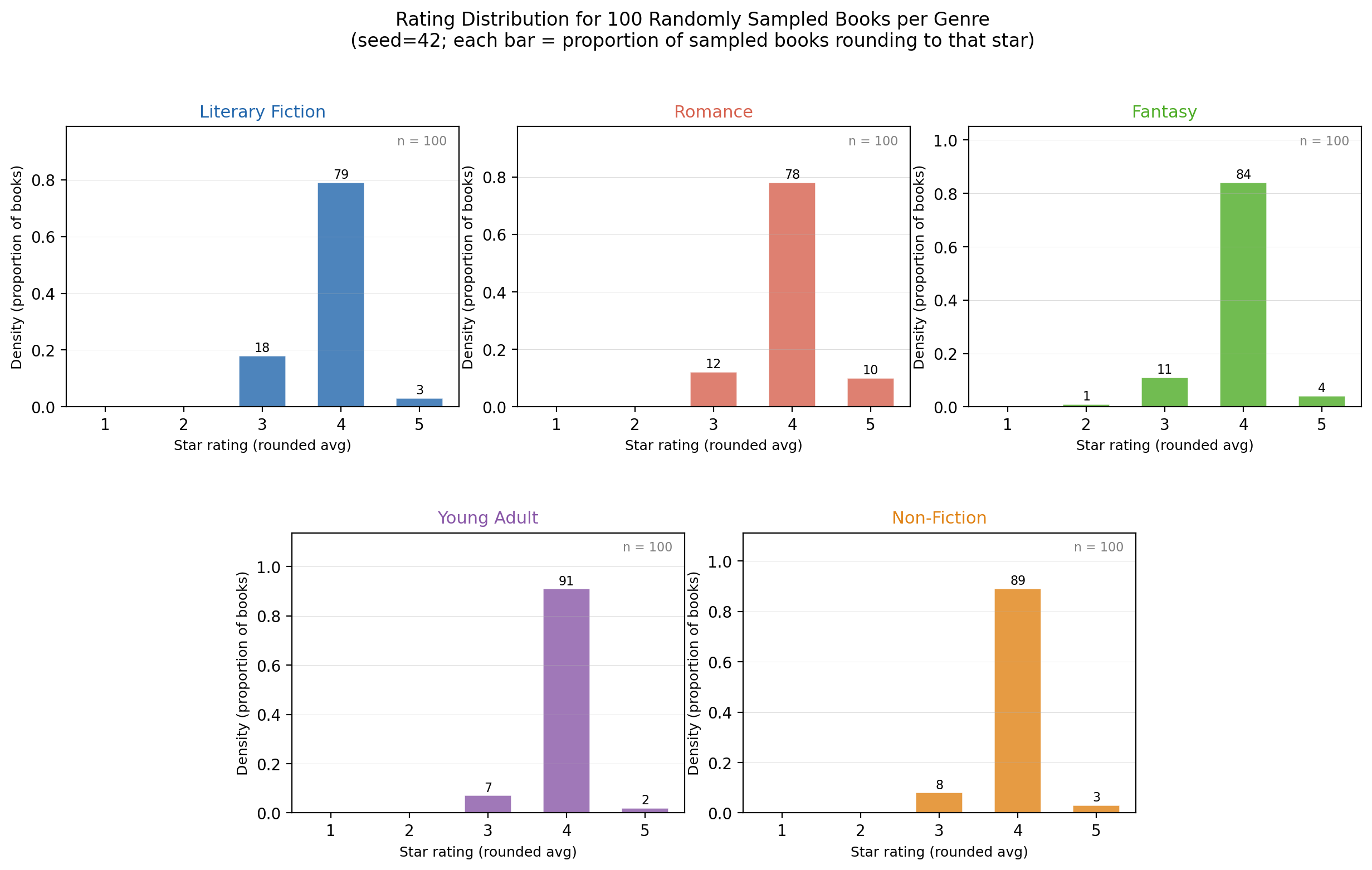
We’ll use the same data used to plot Figure 1, and take the model to it. I take the top 1,000 books per genre, from 2010–2017, and use exact per-book star-count histograms from the raw reviews file (individual star ratings 1–5).
Sample Selection: Choosing the top 1,000 books is a necessary evil (although I could sample more). Think of it as imposing a lower bound for $m_b$ on all books.
First, we want to determine Goodreads’ learning rate and heterogeniety: given its 5-star review system, how many reviews does it take for the platform to learn a book’s true quality? Let $\gamma_H$ and $\gamma_L$ be the distributions of reviewer signals conditional on each quality state (High or Low). This allows us to determine heterogeneity. If $\gamma_H$ and $\gamma_L$ barely overlap, a single review gives the platform a lot of information. If they overlap heavily, each review is noisy and the platform needs many more reviews to learn the state. This makes intuitive sense — if signals are extreme, we need few of them to learn the state.
In the figure below, each of the five panels corresponds to one genre. Within each panel there are two sets of five side-by-side bars — one set for H (high-quality) books and one for L (low-quality) books — showing the empirical probability mass at each star value 1 through 5:
- Green bars — “High quality” books (H): the top third of books in the genre, ranked by their average rating across all reviews. For each book we count the raw number of 1-star, 2-star, …, 5-star reviews it received; the bars show the pooled share across all H books in the genre.
- Red bars — “Low quality” books (L): the bottom third of books by the same ranking. The middle third is discarded to sharpen the contrast between quality states.
The y-axis is the share of reviews in each star bucket (sums to 1 within each quality group).
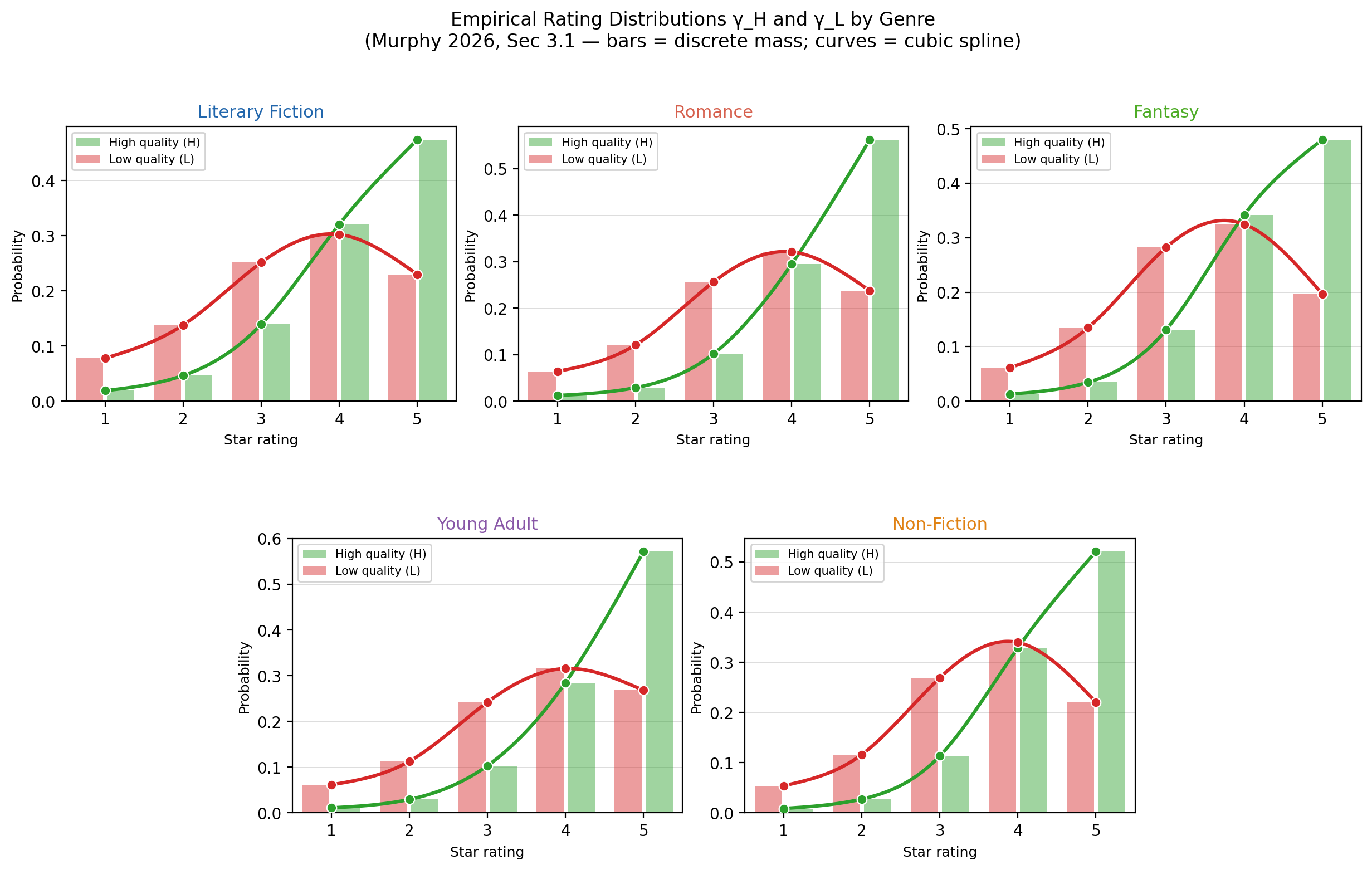
This is a more informative picture of how user signals are distributed on the platform:
- In all genres, H books are concentrated at 4–5 stars (75–87% of H reviews), while L books are more spread (45–55% of L reviews reach 4–5 stars). The 2–3 star region in particular is much denser for L than H. We look at the overlap between H and L splines. The splines diverge at 4 for all genres, which means that 4–5 star books are consistently good picks for me. Put differently, signals $\leq 4$ don’t allow me to confidently distinguish H and L books, and are thus not credible. This matches what we learnt from the Figure 1 rating distribution, which says that books rated $\geq 4$ are good choices.
- Young Adult H books have the most extreme 5-star concentration: 57.2% of all H reviews give 5 stars. Non-Fiction and Romance H also exceed 50% at 5 stars. Literary Fiction H is the least concentrated at 5 (47.4%) and has more mass at 3–4 stars. Young Adult, Non-Fiction, and Romance readers dispense 5-star ratings fairly frequently, which throws a wrench in the $\geq 4$ decision rule. The overall right skew in platform ratings is driven by these genres. Why is this a problem if we expect H books to be better anyway? Ideally, you want the distribution of ratings to be flat (or flat-ish), so that each rating threshold captures meaningful information — in other words, you want tastes to be sufficiently heterogeneous on a 5-star rating system.
- Note that Literary Fiction (which is the genre I happen to care most about) has the most uniform spread across all five stars (8%/14%/25%/30%/23%), resembling an almost flat distribution. The lit-fic distribution is encouraging. If each threshold captures meaningful information, then tastes are sufficiently heterogeneous and we should be able to determine a decision threshold based on averages alone. Things look a little bleak for other genres, where the skew indicates that we might want to pay more attention to the distribution of reviews than the average alone.
Optimal Thresholds
Now that we have a learning rate and have established that the data (for literary fiction) is sufficiently heterogeneous, we want to determine the binary cutoff threshold that will let us pick a good book, solely based on its average rating. If Goodreads replaced its 5-star system with a binary (thumbs-up / thumbs-down) system, what single cutoff point maximises the information the platform retains about book quality?
Each bar represents one genre. The bar height is the optimal cutoff star value: a cutoff of 3 means “rate 3 stars or below = thumbs down; 4 stars or above = thumbs up.” The region $3 < x < 4$ is the ambiguous middle. We can’t say with confidence if these books are good or bad.
The dashed horizontal line at 2.5 is the boundary between symmetric and asymmetric thresholds. Bars above 2.5 (green) represent symmetric or “good/bad” thresholds — the platform is asking “did you like it?” Bars below 2.5 (red, none here) would represent asymmetric “horrible” thresholds (the platform would be asking “was this terrible?” rather than “was this good?”)
Why? When reviewers are heterogeneous, a 1-star review might just mean a mismatch in taste, so the platform gets more information by asking the symmetric question (“did you like it?”) and drawing the line at the midpoint of the signal space.
The $\kappa$ value annotated above each bar is the relative information: the fraction of the full 5-star system’s learning efficiency that the optimal binary system retains.
Aside: By Theorem 1 of Murphy (2026), a binary system is preferred to the 5-star system when binary reviews are submitted at least $1/\kappa$ times as often. The breakeven multipliers are greater than 1 (Literary Fiction: 1.31×; Romance/Non-Fiction/Young Adult: ~1.37–1.38×), which means that we need more reviews for the binary system to be judged against exact star-counts. I’m choosing to ignore this for now.
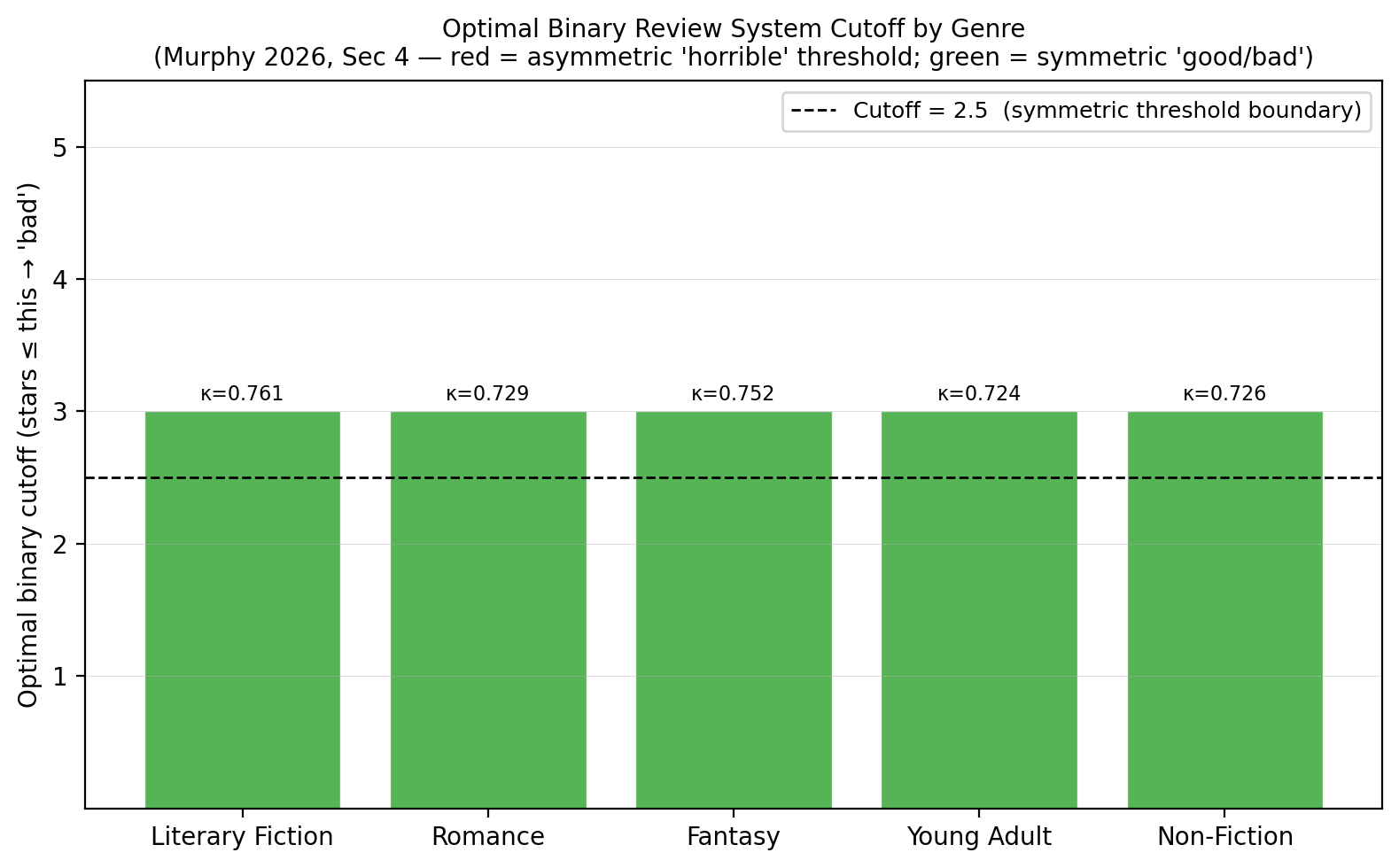
Every genre’s optimal binary system maps 1–3 stars to “bad” and 4–5 stars to “good.” This is the symmetric threshold, coded green. It is consistent with Murphy’s prediction for the heterogeneous-reviewer regime. Note the $\kappa$ value: the penalty of compressing to binary is large — I’m losing over 20% of useful information when I compress my ratings. However, the information loss is the least in literary fiction, because tastes are sufficiently heterogeneous.
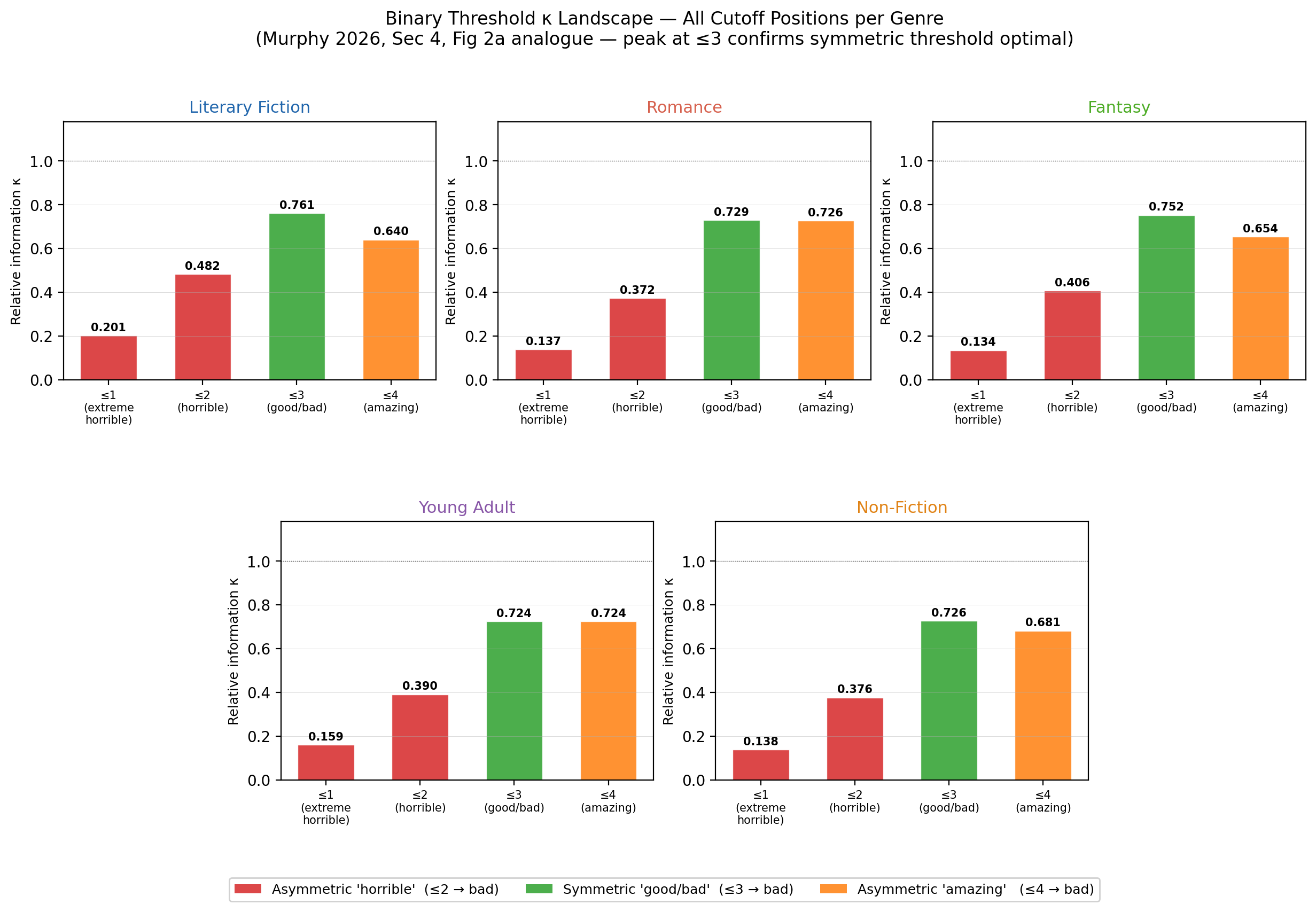
This figure reveals the full empirical $\kappa$ landscape, showing which regime Goodreads occupies and how steep the information penalty is for moving away from the optimum.
For Romance, Young Adult, and (to a lesser extent) Non-Fiction — the symmetric and asymmetric thresholds for good and amazing books are the same. Put differently, on a 5-star scale, the fourth and fifth stars are functionally equivalent to three stars. This makes an optimal decision threshold of 3 iffy, because we have no credible way to differentiate the good from the excellent. In an ideal world, I should be able to differentiate a good romance novel (say, Book Lovers) from an excellent romance novel (Oscar and Lucinda), but it doesn’t look like Goodreads is the ideal setting for that.
In any case, I would like to minimise the possibility of a bad reading experience. For these genres, I will only choose books rated $\geq 4$, since they will be at least good, and possibly amazing (although I will not be able to differentiate this ex-ante).1
Now let’s go back to literary fiction (and fantasy), where good-or-not (symmetric) and amazing-or-horrible (asymmetric) thresholds capture different information. This is excellent news for me, because it means that a threshold rating of $\geq 3$ is a sufficient statistic for me to determine that a book will be at least good, and a rating of $\geq 4$ means that a book will be great. My problem is now solved.2
-
In an ideal world, Goodreads will redesign its rating system for these genres to an asymmetric binary. ↩
-
In practice, I’m not always drawing from the top 1,000 books in a genre, so the rating threshold helps me solve for $m_b$ each time. Determining whether $b$ satisfies my idiosyncratic tastes is still my cross to bear. ↩